Anleitungen
Wie man Redfin scrappt: Python-Leitfaden für Immobiliendaten
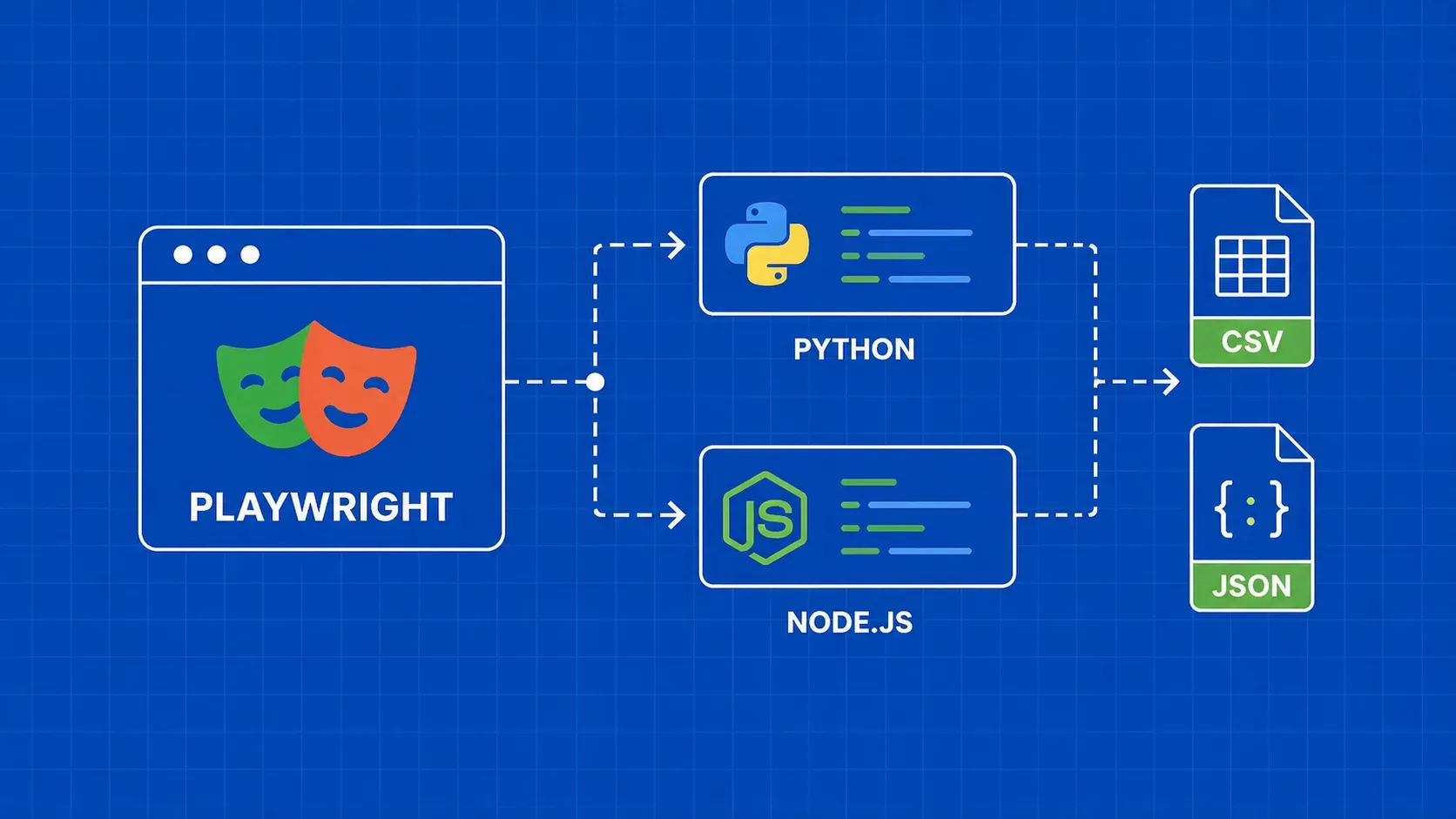
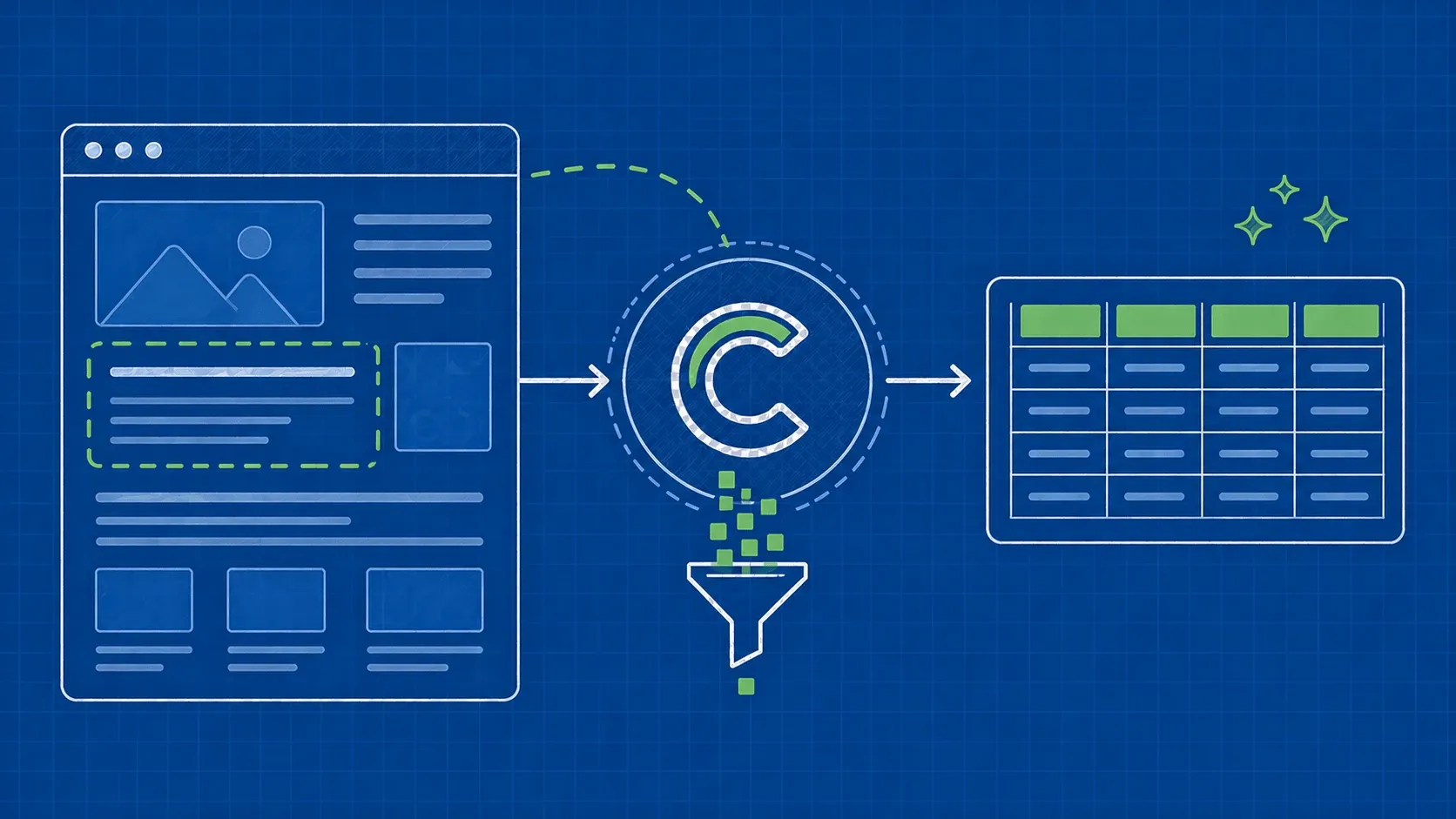
TL;DR: Redfin stellt versteckte API-Endpunkte zur Verfügung, die strukturiertes JSON für Immobilienangebote zurückgeben, wodurch das fragile HTML-Parsing vollständig übersprungen werden kann. Diese Anleitung führt Sie durch den Aufbau eines Python-Scrapers, der Miet- und Verkaufsdaten extrahiert, nach Standort sucht, neue Angebote über XML-Sitemaps überwacht und saubere Ergebnisse in CSV oder JSON exportiert.
Suciu Dan11 min read
Apr 27, 2026